Extracting summarization avec TF-IDF
1. Le Bag of Words
Le sac de mots (BoW) est une technique de traitement du langage naturel (NLP).
La représentation de nos textes sous forme de sac de mot permet de vectoriser notre corpus et ainsi d’avoir une représentation numérique de chaque texte.
Un sac de mots est basé sur l'occurrence des mots dans un document. Le processus commence par l'identification du vocabulaire dans le texte et la mesure de son occurrence.
On parle de sac parce que l'ordre et la structure des mots ne sont pas pris en compte, mais seulement leur occurrence.
La tokenisation
Pour créer un modèle de sac de mots, nous prenons tous les mots d'un corpus et créons une colonne pour chaque mot. Les lignes représentent les phrases. Si un certain mot existe dans la phrase, il est représenté par un 1, et si le mot n'existe pas, il est représenté par un 0. Chaque mot de la colonne représente une seule caractéristique.
Au final, nous obtenons une matrice peu dense (Sparse matrix).
Pour créer un modèle de sac de mots en Python, nous devons effectuer quelques étapes de prétraitement. Ces étapes comprennent la tokenisation et la suppression des mots vides ("stop words").
La tokenisation est le processus de décomposition d'un texte en unités plus petites, généralement des mots.
Vous pouvez effectuer la tokenisation à l'aide de NLTK.
Les "stop words" sont des mots courants en francais, tels que "le, "une" et "à", qui ne contribuent pas à la polarité d'une phrase.
from sklearn.feature_extraction.text import CountVectorizer texts = ["j'aime boire le café tôt le matin", "j'aime boire le thé à quatre heure avec une madelaine"] vectorizer = CountVectorizer() X = vectorizer.fit_transform(texts) print(vectorizer.get_feature_names_out()) print(X.toarray()) import nltk nltk.download('punkt') nltk.download("stopwords") nltk.download('punkt_tab') from nltk.corpus import stopwords from nltk.tokenize import word_tokenize # --- Partie NLTK --- stop_words = set(stopwords.words("french")) filtered_texts = [] for sentence in texts: sentence_clean = sentence.replace("'", " ") # Tokenization words = word_tokenize(sentence_clean, language='french') # Suppression des stop words et de la ponctuation simple filtered_words = [word for word in words if word.lower() not in stop_words and word.isalnum()] # Re-formation de la phrase nettoyée cleaned_sentence = " ".join(filtered_words) filtered_texts.append(cleaned_sentence) print("--- PHRASES FILTRÉES ---") for t in filtered_texts: print(f"Nettoyé : {t}")
sortie :
--- PHRASES FILTRÉES --- Nettoyé : aime boire café tôt matin Nettoyé : aime boire thé quatre heure madelaine
2. La Vectorisation et l'espace vectoriel
Maintenant que notre texte est débarrassé de ses fioritures grammaticales (les stopwords), nous pouvons passer à la vectorisation sémantique brute.
C'est ici qu'intervient la fonction CountVectorizer() de Scikit-Learn.
Son but ? Transformer ces listes de mots nettoyées en une table purement numérique (une matrice), où chaque phrase devient un vecteur positionné dans un espace à $N$ dimensions (où $N$ est la taille de notre vocabulaire global).
# --- Étape 2 : Vectorisation sur le texte filtré --- vectorizer = CountVectorizer() X = vectorizer.fit_transform(filtered_texts) print("\n--- RÉSULTATS COUNT VECTORIZER ---") print("Vocabulaire retenu :") print(vectorizer.get_feature_names_out()) print("\nMatrice (Bag of Words) :") print(X.toarray())
sortie :
--- RÉSULTATS COUNT VECTORIZER --- Vocabulaire retenu : ['aime' 'boire' 'café' 'heure' 'madelaine' 'matin' 'quatre' 'thé' 'tôt'] Matrice (Bag of Words) : [[1 1 1 0 0 1 0 0 1] [1 1 0 1 1 0 1 1 0]]
- Un index est attribué à chaque mot unique du corpus et les mots sont classés par ordre alphabétique.
Par exemple, "aime" est à l'index 0, "boire" est à l'index 1, "madelaine" est à l'index 4, etc. - Chaque ligne de la matrice de documents représente une phrase et chaque colonne correspond à un mot du vocabulaire.
Les valeurs de la matrice représentent la fréquence de chaque mot dans ce document particulier.
[1 1 1 0 0 1 0 0 1] indique que :- Le mot "aime" apparaît une fois (1 à l'indice 0),
- Le mot "boire" apparaît une fois (1 à l'indice 1),
- Le mot "café" apparaît une fois (1 à l'indice 2),
- Le mot "matin" apparaît une fois (1 à l'indice 5),
- Et ainsi de suite.
Le vecteur BoW peut être interprété comme suit :
- Chaque ligne est un vecteur de nombres représentant le nombre de mots. Les dimensions du vecteur sont égales à la taille du vocabulaire.
Dans ce cas, le vocabulaire comporte 9 mots, de sorte que chaque ligne est transformé en un vecteur à 9 dimensions. - La plupart des mots de chaque ligne sont des zéros car chaque document ne contient pas tous les mots du vocabulaire.
Par conséquent, les modèles BoW sont souvent épars, c'est-à-dire qu'ils comportent de nombreux zéros.
3. TF-IDF
1. Attribuer un score à un mot
Nous souhaitons connaître les mots les plus importants de chacun des textes. Pour cela, nous partons du principe que plus un mot est présent dans un texte, plus il est important.
Le score TF (Term Frequency) représente la fréquence d'apparition d'un mot dans une phrase.
avec $f_{i,j}$ le nombre d'apparitions du mot $i$ dans le texte $j$
le score TF n'est pas suffisant pour caractériser l'importance d'un mot dans une phrase.
En effet, les stopwords (mots apparaissant très fréquemment en francais comme "Je", "à", "et"...) ne sont en réalité pas très importants pour comprendre le sens du texte.
Pour corriger ce défaut, nous utiliserons un second principe : plus un mot est spécifique, plus il est important.
Inversement, plus un mot est générique moins il est important.
Cela revient à dire qu'un mot qui apparaît dans beaucoup de textes a moins d'importance dans chacun d'entre eux.
Le score IDF (Inverse Document Frequency) représente donc la spécificité d'un mot dans un corpus de textes.
- $N$ : Nombre total de textes dans le corpus.
- $d_i$ : Nombre de textes contenant le terme $i$.
Désormais, nous avons 2 scores mesurant l'importance d'un mot dans un texte. Pour résumer l'information contenu dans ces 2 scores, nous allons simplement les multiplier.
Le score TF-IDF d'un mot dans une phrase est donc égal à :
Ce score varie de 0 à $+\infty$ . Il est d'autant plus élevé que le mot $i$ est important dans le texte $j$.
Le TfidfVectorizer de scikit-learn est un outil indispensable en Data Science pour transformer un texte brut en une matrice de nombres exploitables par un modèle de Machine Learning.
Pour y parvenir, il combine deux concepts : TF (Term Frequency) et IDF (Inverse Document Frequency).
Son but est de mesurer l'importance d'un mot dans un document par rapport à l'ensemble de votre corpus (votre dataset de textes).
Quand vous lancez un .fit_transform(corpus), le pipeline interne de TfidfVectorizer exécute trois étapes de manière transparente :
[Texte Brut] ➔ [1. CountVectorizer] ➔ [2. TfidfTransformer] ➔ [Matrice TF-IDF]
- La tokenisation et le dictionnaire : Il découpe le texte en mots (tokens), passe tout en minuscules, et construit le vocabulaire global (l'index de toutes les colonnes).
- Le comptage (CountVectorizer) : Il compte les occurrences de chaque mot dans chaque document (matrice de features brutes).
- La pondération (TfidfTransformer) : Il calcule l'IDF global de chaque mot, multiplie les matrices, et normalise le résultat.
Du mot isolé à la comparaison de phrases : La similarité cosinus
Avoir des vecteurs de scores TF-IDF, c'est bien. Mais comment s'en sert-on pour résumer ou trouver des phrases clés ? C'est là qu'intervient la géométrie.
Si deux phrases emploient des mots importants similaires avec des poids TF-IDF proches, leurs vecteurs pointeront dans la même direction dans notre espace mathématique. Une métrique régulièrement utilisée pour mesurer la proximité de ces directions (sans être biaisé par la longueur des phrases) est la similarité cosinus.
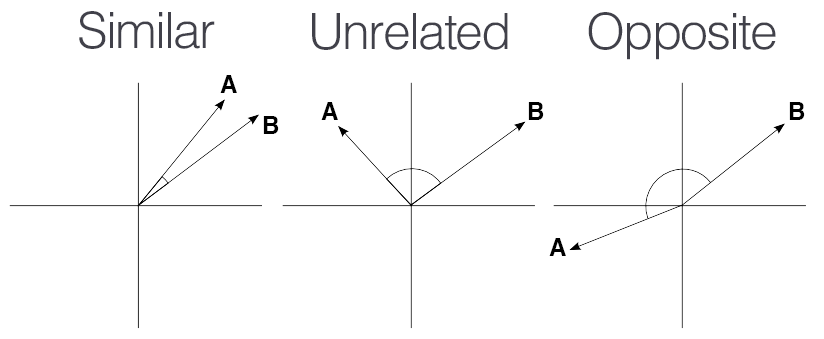
Nous utiliserons la méthode cosine_similarity de Scikit-Learn pour formaliser cette intuition. Voyons tout de suite comment cela se comporte sur un cas concret.
2. Exemple pratique : Analyse d'un flux boursier
Pour illustrer la puissance combinée de TF-IDF et de la similarité cosinus, nous allons étudier un flux RSS traitant de l'entreprise TotalEnergies.
1. Extraction du texte
Pour cet exemple nous allons prendre comme CORPUS un extrait du fichier (3 premières phrases)
[1] Totalenergies: Propulsé par le bond des cours du pétrole, Totalenergies voit son bénéfice trimestriel bondir de 51% à 5,8 milliards de dollars et augmente son dividende [2] (BFM Bourse) - La major pétrolière a livré des résultats trimestriels en très nette hausse au titre des trois premiers mois de l'année, grâce à la hausse des prix de marché. [3] Le débat sur les "super-profits", qui avait agité la classe politique en 2022 et conduit l'exécutif à mettre en place des taxes temporaires, va-t-il resurgir de plus belle?
Soumettons à ce corpus 3 phrases dont nous allons calculer le coefficient de similarité avec le corpus.
[A (très proche)] TotalEnergies enregistre une hausse de son bénéfice grâce aux cours élevés du pétrole. [B (moyennement proche)] Renault publie de bons résultats trimestriels portés par les ventes de véhicules électriques. [C (très éloignée)] Le festival de musique attire des milliers de spectateurs sous un soleil radieux.
# similarity_totalenergies.py # # Corpus : 3 premières phrases de l'article TotalEnergies # + 3 phrases inventées avec des niveaux de similarité différents # # Traitement identique à countvectorize.py : # 1. CountVectorizer brut # 2. Nettoyage NLTK (stop words + ponctuation) # 3. CountVectorizer sur texte filtré + similarité cosinus # 4. TF-IDF sur texte filtré + similarité cosinus # 5. Comparaison des scores # --------------------------------------------------------------------------- # 0. Lecture des 3 premières phrases non-vides du fichier # --------------------------------------------------------------------------- sentences_from_file = [] with open("article_blog_totalenergie.txt", encoding="utf-8") as f: for line in f: line = line.strip() # On ignore les lignes vides, les horodatages et les balises >> if line and not line.startswith(">>") and not line.startswith("mercredi"): sentences_from_file.append(line) if len(sentences_from_file) == 3: break print("=" * 70) print("CORPUS EXTRAIT DU FICHIER (3 premières phrases)") print("=" * 70) for i, s in enumerate(sentences_from_file, 1): print(f"[{i}] {s}\n") # --------------------------------------------------------------------------- # 1. Phrases inventées (niveaux de similarité volontairement différents) # - Phrase A : très proche du corpus (pétrole, bénéfice, TotalEnergies) # - Phrase B : moyennement proche (résultats financiers, autre secteur) # - Phrase C : très éloignée (sujet sans rapport) # --------------------------------------------------------------------------- invented_sentences = [ # Proche : mots-clés pétrole / bénéfice / hausse "TotalEnergies enregistre une hausse de son bénéfice grâce aux cours élevés du pétrole.", # Moyenne : résultats financiers mais secteur différent "Renault publie de bons résultats trimestriels portés par les ventes de véhicules électriques.", # Éloignée : tout autre sujet "Le festival de musique attire des milliers de spectateurs sous un soleil radieux.", ] print("=" * 70) print("PHRASES INVENTÉES") print("=" * 70)
Output :
====================================================================== CORPUS EXTRAIT DU FICHIER (3 premières phrases) ====================================================================== [1] Totalenergies: Propulsé par le bond des cours du pétrole, Totalenergies voit son bénéfice trimestriel bondir de 51% à 5,8 milliards de dollars et augmente son dividende [2] (BFM Bourse) - La major pétrolière a livré des résultats trimestriels en très nette hausse au titre des trois premiers mois de l'année, grâce à la hausse des prix de marché. [3] Le débat sur les "super-profits", qui avait agité la classe politique en 2022 et conduit l'exécutif à mettre en place des taxes temporaires, va-t-il resurgir de plus belle? ====================================================================== PHRASES INVENTÉES ====================================================================== [A (très proche)] TotalEnergies enregistre une hausse de son bénéfice grâce aux cours élevés du pétrole. [B (moyennement proche)] Renault publie de bons résultats trimestriels portés par les ventes de véhicules électriques. [C (très éloignée)] Le festival de musique attire des milliers de spectateurs sous un soleil radieux. ======================================================================
2. Vectorisation Bag-of-Words (CountVectorizer)
`CountVectorizer` (scikit-learn) transforme chaque phrase en vecteur de comptage de mots.
labels = ["A (très proche)", "B (moyennement proche)", "C (très éloignée)"] for label, s in zip(labels, invented_sentences): print(f"[{label}] {s}\n") # Corpus complet = 3 phrases fichier + 3 phrases inventées all_texts = sentences_from_file + invented_sentences n_file = len(sentences_from_file) # 3 n_all = len(all_texts) # 6 # --------------------------------------------------------------------------- # 2. CountVectorizer brut (sans nettoyage) # --------------------------------------------------------------------------- from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import numpy as np vectorizer_raw = CountVectorizer() X_raw = vectorizer_raw.fit_transform(all_texts) print("=" * 70) print("ÉTAPE 1 — CountVectorizer BRUT (sans nettoyage)") print("=" * 70) print("Vocabulaire :", vectorizer_raw.get_feature_names_out()) print("\nMatrice Bag-of-Words :\n", X_raw.toarray())
Output :
ÉTAPE 1 — CountVectorizer BRUT (sans nettoyage) ====================================================================== Vocabulaire : ['2022' '51' 'agité' 'année' 'attire' 'au' 'augmente' 'aux' 'avait' 'belle' 'bfm' 'bond' 'bondir' 'bons' 'bourse' 'bénéfice' 'classe' 'conduit' 'cours' 'de' 'des' 'dividende' 'dollars' 'du' 'débat' 'en' 'enregistre' 'et' 'exécutif' 'festival' 'grâce' 'hausse' 'il' 'la' 'le' 'les' 'livré' 'major' 'marché' 'mettre' 'milliards' 'milliers' 'mois' 'musique' 'nette' 'par' 'place' 'plus' 'politique' 'portés' 'premiers' 'prix' 'profits' 'propulsé' 'publie' 'pétrole' 'pétrolière' 'qui' 'radieux' 'renault' 'resurgir' 'résultats' 'soleil' 'son' 'sous' 'spectateurs' 'super' 'sur' 'taxes' 'temporaires' 'titre' 'totalenergies' 'trimestriel' 'trimestriels' 'trois' 'très' 'un' 'une' 'va' 'ventes' 'voit' 'véhicules' 'électriques' 'élevés'] Matrice Bag-of-Words : [[0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 1 0 0 1 2 1 1 1 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 2 1 0 0 0 0 0 0 0 1 0 0 0] [0 0 0 1 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 2 3 0 0 0 0 1 0 0 0 0 1 2 0 2 0 0 1 1 1 0 0 0 1 0 1 0 0 0 0 0 1 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 1 1 0 0 0 0 0 0 0 0] [1 0 1 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 1 2 0 1 1 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0] [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1] [0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 1 1 0] [0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]]
3. Nettoyage avec NLTK
- Téléchargement des ressources NLTK nécessaires (`punkt`, `stopwords`).
- Suppression des *stop words* français (mots courants sans valeur discriminante : « le », « à », etc.).
- Tokenisation de chaque phrase, puis filtrage des tokens non-alphanumériques.
# --------------------------------------------------------------------------- # 3. Nettoyage NLTK # --------------------------------------------------------------------------- import nltk nltk.download("punkt", quiet=True) nltk.download("stopwords", quiet=True) nltk.download("punkt_tab", quiet=True) from nltk.corpus import stopwords from nltk.tokenize import word_tokenize stop_words = set(stopwords.words("french")) def clean_text(sentence: str) -> str: sentence = sentence.replace("'", " ").replace("'", " ") words = word_tokenize(sentence, language="french") filtered = [w for w in words if w.lower() not in stop_words and w.isalnum()] return " ".join(filtered) filtered_texts = [clean_text(s) for s in all_texts] print("\n" + "=" * 70) print("ÉTAPE 2 — TEXTES APRÈS NETTOYAGE NLTK") print("=" * 70) text_labels = [f"Fichier {i+1}" for i in range(n_file)] + ["Inventée A", "Inventée B", "Inventée C"] for label, t in zip(text_labels, filtered_texts): print(f"[{label}] {t}")
Output :
====================================================================== ÉTAPE 2 — TEXTES APRÈS NETTOYAGE NLTK ====================================================================== [Fichier 1] Totalenergies Propulsé bond cours pétrole Totalenergies voit bénéfice trimestriel bondir 51 milliards dollars augmente dividende [Fichier 2] BFM Bourse major pétrolière a livré résultats trimestriels très nette hausse titre trois premiers mois année grâce hausse prix marché [Fichier 3] débat agité classe politique 2022 conduit exécutif mettre place taxes temporaires resurgir plus belle [Inventée A] TotalEnergies enregistre hausse bénéfice grâce cours élevés pétrole [Inventée B] Renault publie bons résultats trimestriels portés ventes véhicules électriques [Inventée C] festival musique attire milliers spectateurs sous soleil radieux
4. Calcul de similarité
- Un second CountVectorizer est appliqué sur les phrases filtrées pour obtenir un vocabulaire plus pertinent.
- Calcul de la matrice de similarité
# --------------------------------------------------------------------------- # 4. CountVectorizer sur texte filtré + similarité cosinus # --------------------------------------------------------------------------- vectorizer = CountVectorizer() X_cv = vectorizer.fit_transform(filtered_texts) sim_cv = cosine_similarity(X_cv) print("\n" + "=" * 70) print("ÉTAPE 3 — SIMILARITÉ COSINUS (CountVectorizer, texte filtré)") print("=" * 70) print("\nMatrice de similarité complète :\n") # Affichage formaté header = f"{'':16}" + "".join(f"{l:>14}" for l in text_labels) print(header) for i, row_label in enumerate(text_labels): row = f"{row_label:16}" + "".join(f"{sim_cv[i][j]:>14.4f}" for j in range(n_all)) print(row)
Output :
======================================================================
ÉTAPE 3 — SIMILARITÉ COSINUS (CountVectorizer, texte filtré)
======================================================================
Matrice de similarité complète :
Fichier 1 Fichier 2 Fichier 3 Inventée A Inventée B Inventée C
Fichier 1 1.0000 0.0000 0.0000 0.4287 0.0000 0.0000
Fichier 2 0.0000 1.0000 0.0000 0.2315 0.1455 0.0000
Fichier 3 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000
Inventée A 0.4287 0.2315 0.0000 1.0000 0.0000 0.0000
Inventée B 0.0000 0.1455 0.0000 0.0000 1.0000 0.0000
Inventée C 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
5. Affichage des scores
On établie le "score" final d'une phrase inventée comme la moyenne arithmétique des similarités cosinus calculées entre cette phrase et chacune des phrases du corpus de référence.
print("\nScores des phrases inventées vs corpus (fichier) :") for inv_idx, inv_label in enumerate(["A", "B", "C"]): col = n_file + inv_idx scores = [sim_cv[row][col] for row in range(n_file)] mean_score = np.mean(scores) print(f" Phrase inventée {inv_label} — scores : {[round(s,4) for s in scores]} | moyenne : {mean_score:.4f}")
Output :
Scores des phrases inventées vs corpus (fichier) : Phrase inventée A — scores : [np.float64(0.4287), np.float64(0.2315), np.float64(0.0)] | moyenne : 0.2201 Phrase inventée B — scores : [np.float64(0.0), np.float64(0.1455), np.float64(0.0)] | moyenne : 0.0485 Phrase inventée C — scores : [np.float64(0.0), np.float64(0.0), np.float64(0.0)] | moyenne : 0.0000
6. Vectorisation TF-IDF (TfidfVectorizer) et calculs des similarités
TfidfVectorizer pondère les mots selon leur fréquence dans le document (*TF*) et leur rareté dans le corpus (*IDF*), produisant des scores décimaux entre 0 et 1.
# --------------------------------------------------------------------------- # 5. TF-IDF sur texte filtré + similarité cosinus # --------------------------------------------------------------------------- tfidf_vectorizer = TfidfVectorizer() X_tfidf = tfidf_vectorizer.fit_transform(filtered_texts) sim_tfidf = cosine_similarity(X_tfidf) print("\n" + "=" * 70) print("ÉTAPE 4 — SIMILARITÉ COSINUS (TF-IDF, texte filtré)") print("=" * 70) print("\nMatrice de similarité complète :\n") print(header) for i, row_label in enumerate(text_labels): row = f"{row_label:16}" + "".join(f"{sim_tfidf[i][j]:>14.4f}" for j in range(n_all)) print(row)
Output :
======================================================================
ÉTAPE 4 — SIMILARITÉ COSINUS (TF-IDF, texte filtré)
======================================================================
Matrice de similarité complète :
Fichier 1 Fichier 2 Fichier 3 Inventée A Inventée B Inventée C
Fichier 1 1.0000 0.0000 0.0000 0.3569 0.0000 0.0000
Fichier 2 0.0000 1.0000 0.0000 0.1899 0.1076 0.0000
Fichier 3 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000
Inventée A 0.3569 0.1899 0.0000 1.0000 0.0000 0.0000
Inventée B 0.0000 0.1076 0.0000 0.0000 1.0000 0.0000
Inventée C 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
7. Affichage des scores par la vectorisation TF-IDF
print("\nScores des phrases inventées vs corpus (fichier) :")
for inv_idx, inv_label in enumerate(["A", "B", "C"]):
col = n_file + inv_idx
scores = [sim_tfidf[row][col] for row in range(n_file)]
mean_score = np.mean(scores)
print(f" Phrase inventée {inv_label} — scores : {[round(s,4) for s in scores]} | moyenne : {mean_score:.4f}")
Output :
Scores des phrases inventées vs corpus (fichier) : Phrase inventée A — scores : [np.float64(0.3569), np.float64(0.1899), np.float64(0.0)] | moyenne : 0.1822 Phrase inventée B — scores : [np.float64(0.0), np.float64(0.1076), np.float64(0.0)] | moyenne : 0.0359 Phrase inventée C — scores : [np.float64(0.0), np.float64(0.0), np.float64(0.0)] | moyenne : 0.0000
8. Comparaison CountVectorizer vs TF-IDF
# --------------------------------------------------------------------------- # 6. Comparaison CountVectorizer vs TF-IDF # --------------------------------------------------------------------------- print("\n" + "=" * 70) print("ÉTAPE 5 — COMPARAISON CountVectorizer vs TF-IDF") print("(score moyen de chaque phrase inventée contre le corpus)") print("=" * 70) print(f"\n{'Phrase inventée':25} {'CountVectorizer':>18} {'TF-IDF':>12}") print("-" * 57) for inv_idx, inv_label in enumerate(["A (très proche)", "B (moy. proche)", "C (très éloignée)"]): col = n_file + inv_idx mean_cv = np.mean([sim_cv[r][col] for r in range(n_file)]) mean_tfidf = np.mean([sim_tfidf[r][col] for r in range(n_file)]) print(f"{inv_label:25} {mean_cv:>18.4f} {mean_tfidf:>12.4f}") print()
Output :
===================================================================== ÉTAPE 5 — COMPARAISON CountVectorizer vs TF-IDF (score moyen de chaque phrase inventée contre le corpus) ====================================================================== Phrase inventée CountVectorizer TF-IDF --------------------------------------------------------- A (très proche) 0.2201 0.1822 B (moy. proche) 0.0485 0.0359 C (très éloignée) 0.0000 0.0000
On a vérifié que la phrase A (très proche) obtient une moyenne de score bien plus élevée que la phrase C (très éloignée) lorsqu'on les confronte aux phrases du fichier.
3. Test de qualité de l'algorithme : L'Analyse de Sentiment comme validation sémantique
Lorsque l'on crée un algorithme de résumé automatique (ici par extraction de phrases), on se heurte à un problème majeur : comment s'assurer que le résumé ne trahit pas le texte d'origine ?
Avant même de calculer des métriques purement mathématiques de chevauchement de mots, nous pouvons réaliser un test de "cohérence sémantique" en utilisant le Deep Learning. L'idée est simple : nous allons soumettre le texte complet ET le résumé généré par notre formule TF-IDF à un modèle de langage (Transformer) spécialisé dans l'analyse de sentiment financier.
L'objectif :
Si l'article original est jugé très positif par l'IA (par exemple, suite à l'annonce de gros bénéfices), le résumé extrait doit impérativement obtenir la même polarité. Si le résumé bascule au neutre ou au négatif, cela signifie que notre moteur TF-IDF a raté les phrases cruciales et a dénaturé le message économique global.
Ce programme est un pipeline complet de Traitement Automatique du Langage Naturel (NLP) appliqué au domaine de la finance.
Il prend un article de blog sur TotalEnergies, en extrait un résumé via une approche statistique (TF-IDF), évalue mathématiquement la qualité de ce résumé (Scores ROUGE), puis compare l'humeur du texte original avec celle du résumé à l'aide d'un modèle de Deep Learning (Analyse de sentiment).
1. Préparation et Nettoyage (Prétraitement)
- Le programme commence par définir une liste de mots vides (stop words) personnalisée.
- Il combine les mots vides standards de la langue française (via spacy) avec des mots spécifiques au domaine de l'article (ex: "totalenergies", "milliards", "trimestre") qui n'apportent pas de valeur sémantique pour le résumé.
- Il utilise nltk pour découper le texte original en phrases individuelles.
- Découpage du texte en phrases avec nltk.sent_tokenize.
- Lemmatisation de chaque phrase avec spaCy : chaque mot est remplacé par sa forme canonique (ex. "bondir" → "bondir", "résultats" → "résultat"). Cela améliore la qualité des scores TF-IDF.
import nltk import numpy as np import spacy as np from sklearn.feature_extraction.text import TfidfVectorizer from spacy.lang.fr.stop_words import STOP_WORDS as STOP_WORDS_FR from transformers import pipeline # Mots très fréquents dans cet article mais peu discriminants (sujet, unités monétaires, périodes) DOMAIN_STOP_WORDS = { "totalenergies", "groupe", "entreprise", "société", "dollars", "milliards", "millions", "trimestre", "premier", "an", } CUSTOM_STOP_WORDS = STOP_WORDS_FR | DOMAIN_STOP_WORDS # Chargement du modèle spaCy français pour la lemmatisation nlp = spacy.load("fr_core_news_sm", quiet=True) # Téléchargement silencieux des ressources NLTK nécessaires pour le découpage en phrases nltk.download("punkt_tab", quiet=True) def lemmatiser(phrase): # Retourne une phrase dont chaque mot est remplacé par son lemme (en minuscules). doc = nlp(phrase) return " ".join(token.lemma_.lower() for token in doc if not token.is_space)
2.Le moteur de résumé : resumer_texte_tfidf
C'est le cœur du programme. Il fonctionne selon cette logique :
- Vectorisation : Il transforme chaque phrase en un vecteur numérique grâce à TfidfVectorizer. Ce calcul attribue un score à chaque mot : plus un mot est rare dans l'ensemble du texte mais présent dans une phrase précise, plus son score est élevé.
- Scoring : Le score d'une phrase est calculé en faisant la somme des scores TF-IDF de tous les mots qu'elle contient.
- Sélection : Le programme identifie les $n$ phrases ayant obtenu les scores les plus élevés (les plus "informatives") et les réassemble dans leur ordre d'apparition d'origine pour former le résumé final.
Dans la fonction principale, le programme charge un article spécifique (ici sur "TotalEnergies"), génère un résumé de 3 phrases, puis affiche les différents scores de performance calculés.
def resumer_texte_tfidf(texte, n_phrases=3, lang="french", extra_stop_words=None, ngram_range=(1, 1)): # Découpage du texte en phrases phrases = nltk.sent_tokenize(texte, language=lang) if len(phrases) <= n_phrases: return texte # Fusion des stop words de base avec les éventuels stop words supplémentaires stop_words = CUSTOM_STOP_WORDS | set(extra_stop_words) if extra_stop_words else CUSTOM_STOP_WORDS # Extraction des features via TF-IDF (on retire les stop words et on utilise les n-grams) vectorizer = TfidfVectorizer(stop_words=list(stop_words), ngram_range=ngram_range) tfidf_matrix = vectorizer.fit_transform(phrases) # Somme des scores TF-IDF pour chaque phrase scores_phrases = np.array(tfidf_matrix.sum(axis=1)).flatten() # Sélection des N meilleures phrases (triées par index pour garder la chronologie) meilleurs_index = np.argsort(scores_phrases)[-n_phrases:] meilleurs_index.sort() return " ".join([phrases[i] for i in meilleurs_index]) def main(): print("Hello from tfidf!") fichier = "article_blog_totalenergie.txt" with open(fichier, encoding="utf-8") as f: texte_source = f.read() print("\n--- Texte source original (Extrait) ---") print(texte_source[:1000] + "...\n") # Application de l'lgo TF-IDF avec stop words enrichis nb_phrases = 3 print(f"--- Résumé automatique généré (TF-IDF - {nb_phrases} phrases) ---") resume = resumer_texte_tfidf(texte_source, n_phrases=nb_phrases, ngram_range=(1, 2)) print(resume) reference = texte_source.lower().split() first_summary = resume.lower().split()
- Découpage du texte en phrases avec nltk.sent_tokenize.
- Lemmatisation de chaque phrase avec spaCy :
chaque mot est remplacé par sa forme canonique (ex. "bondir" → "bondir", "résultats" → "résultat"). Cela améliore la qualité des scores TF-IDF. - Vectorisation TF-IDF sur les phrases lemmatisées, en excluant :
- les stop words français (spaCy)
- des mots de domaine peu discriminants définis manuellement ("totalenergies", "dollars", "milliards", "trimestre", etc.)
- la plage de n-grammes (1,2) : unigrammes ET bigrammes sont pris en compte.
- Pour chaque phrase, la somme de ses scores TF-IDF est calculée :
cela reflète la "densité informationnelle" de la phrase. - Les 3 phrases au score le plus élevé sont sélectionnées et restituées dans leur ordre d'apparition original.
3.Évaluation par les scores ROUGE
Les scores ROUGE mesurent le chevauchement entre le résumé généré et le texte de référence (le texte source complet).
- Precision_n : proportion des n-grammes du résumé présents dans la référence.
- Recall_n : proportion des n-grammes de la référence présents dans le résumé.
- ROUGE_n : moyenne harmonique (F1) de Precision_n et Recall_n.
La fonction n_gram(liste, n) est un utilitaire qui transforme une liste de mots en liste de n-grammes consécutifs.
def Precision_1(ref, summary): """ Calcule le score Precision_1 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ N = len(summary) d = 0 for word in summary: if word in ref: d+=1 return d/N def Recall_1(ref, summary): """ Calcule le score Recall_1 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ N = len(ref) d = 0 for word in ref : if word in summary: d+=1 return d/N #Enfin, pour prendre en compte les informations contenues # à la fois dans la précision et le rappel, nous allons pouvoir calculer le score F1, que l'on appellera ici ROUGE1 def ROUGE_1(ref, summary): """ Calcule le score Rouge_1 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ if Precision_1(ref, summary)+Recall_1(ref, summary) == 0 : print(0) else: return 2*Precision_1(ref, summary)*Recall_1(ref, summary)/(Precision_1(ref, summary)+Recall_1(ref, summary)) def n_gram(resume, n): """ Transforme une liste de mots en une liste de n-grams. resume : Liste de mots. n : nombre de mots dans un groupe de mots. """ result = [] for i in range(len(resume) + 1 - n): n_gram = resume[i] for j in range(i+1, n+i): n_gram += ' ' + resume[j] result.append(n_gram) return result def Precision_2(ref, summary): """ Calcule le score Precision_2 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ return Precision_1(n_gram(ref, 2), n_gram(summary, 2)) def Recall_2(ref, summary): """ Calcule le score Recall_2 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ return Recall_1(n_gram(ref, 2), n_gram(summary, 2)) def ROUGE_2(ref, summary): """ Calcule le score Rouge_2 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ return ROUGE_1(n_gram(ref, 2), n_gram(summary, 2)) def Precision_3(ref, summary): """ Calcule le score Rouge_1 de summary par rapport à ref. ref : Liste de mots. summary : liste de mots. """ return Precision_1(n_gram(ref, 3), n_gram(summary, 3)) def Recall_3(ref, summary): return Recall_1(n_gram(ref, 3), n_gram(summary, 3)) def ROUGE_3(ref, summary): return ROUGE_1(n_gram(ref, 3), n_gram(summary, 3)) def Precision_4(ref, summary): return Precision_1(n_gram(ref, 4), n_gram(summary, 4)) def Recall_4(ref, summary): return Recall_1(n_gram(ref, 4), n_gram(summary, 4)) def ROUGE_4(ref, summary): return ROUGE_1(n_gram(ref, 4), n_gram(summary, 4))
4. Analyse de sentiment financier
Le modèle Transformer "bardsai/finance-sentiment-fr-base" classe le texte en :
- POSITIVE : note 2/2.
- NEUTRAL : note 1/2.
- RNEGATIVE : note 0/2.
L'analyse est réalisée deux fois : sur le résumé, puis sur le texte source complet (tronqué à 512 tokens, limite du modèle), afin de comparer les sentiments perçus.
# Initialisation globale (une seule fois en mémoire)
finance_classifier = pipeline(
"sentiment-analysis",
model="bardsai/finance-sentiment-fr-base",
)
def analyser_sentiment_finance(texte):
"""Analyse le sentiment financier du texte et retourne un label, une note (0-2) et la confiance."""
resultat = finance_classifier(texte[:512])[0]
label = resultat["label"]
confiance = resultat["score"]
mapping_score = {
"positive": 2,
"neutral": 1,
"negative": 0,
}
note = mapping_score.get(label.lower(), 1)
return label, note, confiance
def main():
print("Hello from tfidf!")
fichier = "article_blog_totalenergie.txt"
with open(fichier, encoding="utf-8") as f:
texte_source = f.read()
print("\n--- Texte source original (Extrait) ---")
print(texte_source[:1000] + "...\n")
# Application de ton algo TF-IDF avec stop words enrichis et bigrammes
nb_phrases = 3
print(f"--- Résumé automatique généré (TF-IDF - {nb_phrases} phrases) ---")
resume = resumer_texte_tfidf(texte_source, n_phrases=nb_phrases, ngram_range=(1, 2))
print(resume)
reference = texte_source.lower().split()
first_summary = resume.lower().split()
print('Precision_1(reference, first_summary) =', Precision_1(reference, first_summary))
print('Recall-1(reference, first_summary) = ', Recall_1(reference, first_summary))
print('ROUGE-1(reference, first_summary) =', ROUGE_1(reference, first_summary))
print('ROUGE_2(reference, first_summary) =', ROUGE_2(reference, first_summary))
print('ROUGE-3(reference, first_summary) =', ROUGE_3(reference, first_summary))
print('ROUGE-4(reference, first_summary) =', ROUGE_4(reference, first_summary))
#print('N_gram 2 = ',n_gram(reference, 2))
print("\n--- Analyse de Sentiment Financier resumé---")
label, note, confiance = analyser_sentiment_finance(resume)
print(f"Sentiment détecté : {label.upper()}")
print(f"Confiance du modèle : {confiance:.2%}")
print(f"Note finale pour TotalEnergies : {note}/2")
print("\n--- Analyse de Sentiment Financier texte_source---")
label, note, confiance = analyser_sentiment_finance(texte_source)
print(f"Sentiment détecté : {label.upper()}")
print(f"Confiance du modèle : {confiance:.2%}")
print(f"Note finale pour TotalEnergies : {note}/2")
if __name__ == "__main__":
main()
Output 1:
Hello from tfidf! --- Texte source original (Extrait) --- Totalenergies: Propulsé par le bond des cours du pétrole, Totalenergies voit son bénéfice trimestriel bondir de 51% à 5,8 milliards de dollars et augmente son dividende mercredi 29 avril 2026 à 08h03 (BFM Bourse) - La major pétrolière a livré des résultats trimestriels en très nette hausse au titre des trois premiers mois de l'année, grâce à la hausse des prix de marché. Le débat sur les "super-profits", qui avait agité la classe politique en 2022 et conduit l'exécutif à mettre en place des taxes temporaires, va-t-il resurgir de plus belle? Totalenergies a en tout cas publié, ce mercredi 29 avril, des comptes trimestriels en nette amélioration, tirés par la hausse des cours des hydrocarbures, elle-même due à l'éclatement du conflit en Iran, fin février. >>Accédez à nos analyses graphiques exclusives, et entrez dans la confidence du Portefeuille Trading De janvier à mars, la société a dégagé un bénéfice net consolidé de 5,8 milliards de dollars (soit 5 milliards d'euros), en hausse...
Output 2:
--- Résumé automatique généré (TF-IDF - 3 phrases) --- /home/shaky/projets/classification_textes/tfidf/.venv/lib/python3.13/site-packages/sklearn/feature_extraction/text.py:411: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['neuf', 'qu', 'quelqu'] not in stop_words. warnings.warn( Totalenergies: Propulsé par le bond des cours du pétrole, Totalenergies voit son bénéfice trimestriel bondir de 51% à 5,8 milliards de dollars et augmente son dividende mercredi 29 avril 2026 à 08h03 (BFM Bourse) - La major pétrolière a livré des résultats trimestriels en très nette hausse au titre des trois premiers mois de l'année, grâce à la hausse des prix de marché.p>Output 3:
"Nous nous attendons à une réaction positive aux résultats, le bénéfice dépassant d'environ 5% les prévisions du consensus et de 10 % nos estimations, l'impact de la crise au Moyen-Orient étant largement compensé par l'amélioration de la conjoncture économique et les solides performances opérationnelles enregistrées ailleurs", développe la banque britannique.
"En 2026, la croissance de notre production à valeur ajoutée devrait provenir en grande majorité de l'extérieur du Moyen-Orient, ce qui signifie qu'une hausse du prix du pétrole compensera largement la baisse de la production au Moyen-Orient : une augmentation de 8 dollars le baril du prix duBrentsuffirait à compenser le flux de trésorerie d'exploitation (CFFO) prévu pour 2026 provenant de nos actifs offshore en Irak, au Qatar et aux Émirats arabes unis, à un prix de 60 dollars le baril", indiquait alorsTotalenergies.
recision_1(reference, first_summary) = 1.0 Recall-1(reference, first_summary) = 0.5264705882352941 ROUGE-1(reference, first_summary) = 0.6897880539499037 ROUGE_2(reference, first_summary) = 0.41557565069277336 ROUGE-3(reference, first_summary) = 0.3461368202404059 ROUGE-4(reference, first_summary) = 0.3173839632762896 --- Analyse de Sentiment Financier resumé--- Sentiment détecté : POSITIVE Confiance du modèle : 99.97% Note finale pour TotalEnergies : 2/2 --- Analyse de Sentiment Financier texte_source--- Sentiment détecté : POSITIVE Confiance du modèle : 99.97% Note finale pour TotalEnergies : 2/2
Ce test valide la capacité de notre algorithme TF-IDF à préserver l'alignement contextuel et le ton de l'article d'origine.
Si le modèle de Transformer extrait un sentiment identique (par exemple, une orientation "POSITIVE" avec un fort taux de confiance sur les deux versions), cela démontre que l'extraction des phrases clés n'a pas dénaturé le message économique global.
Néanmoins, bien que l'analyse de sentiment confirme la fidélité de l'ambiance générale, elle ne permet pas de mesurer précisément le taux de compression ni la structure lexicale exacte du résumé.
C'est pourquoi il est indispensable de corréler ces résultats sémantiques à des critères mathématiques standardisés, introduits par la métrique ROUGE.
4. Rappel sur la métrique rouge
La métrique ROUGE (Recall-Oriented Understudy for Gisting Evaluation) permet d'estimer la qualité d'un résumé, en le comparant à un résumé de référence.
Pour cela, l'idée est de calculer la proportion de mots que la référence et le résumé ont en commun.
Selon qu'on mette au dénominateur les mots de la référence ou du résumé, cela nous amène à calculer ce qui s'apparente à la précision et au rappel du résumé.
1. Precision
Nous cherchons ici à calculer la proportion de mots du résumé qui se trouvent également dans la référence. Ce score est appelé Precision1 :
- $N_{\text{sum}}$ : nombre de mots dans sum
- $\delta_i = 1$ si le mot $i$ est dans ref, 0 sinon.
2. Recall
Proportion de mots de la référence qui se trouvent également dans le résumé :
- $N_{\text{ref}}$ : nombre de mots dans ref
- $\delta_i = 1$ si mot $i$ est dans sum, 0 sinon.
3. ROUGE-1
Enfin, pour prendre en compte les informations contenues à la fois dans la précision et le rappel, nous allons pouvoir calculer le score F1, que l'on appellera ici ROUGE1 :
Score entre 0 et 1. Plus il est élevé, plus le résumé est fidèle.
n-gram
le score ROUGE1 est uniquement basé sur la présence ou l'absence des mots dans le résumé. Pourtant, certains mots peuvent avoir des sens très différents en fonction du contexte dans lequel ils sont employés.
Afin de corriger cette faiblesse, il est nécessaire de prendre en compte la présence ou l'absence de groupe de mots(bag of words) plutôt que des mots eux-mêmes. Un groupe de n
mots est appelé un n-gram.
Créons une fonction n_gram, qui prend en argument un résumé et un entier 𝑛, et qui renvoie la liste de tous les 𝑛-grams de ce résumé.
def n_gram(resume, n): """ Transforme une liste de mots en une liste de n-grams. resume : Liste de mots. n : nombre de mots dans un groupe de mots. """ result = [] for i in range(len(resume) + 1 - n): n_gram = resume[i] for j in range(i+1, n+i): n_gram += ' ' + resume[j] result.append(n_gram) return result
Nous appelons Precision2, Recall2, et ROUGE2 les scores correspondant aux définitions précédentes mais en utilisant des 2-grams au lieu des mots uniques.
Pour calculer ces scores, il nous suffit d'appliquer les fonctions Precision1, Recall1, et ROUGE1 sur des 2-grams.
La métrique ROUGE est très facile à utiliser est relativement bonne pour comparer des résumés. Néanmoins, elle a tout de même certains défauts :
Elle ne détecte pas les erreurs de syntaxe ou les contre-sens. Ainsi, un texte complètement insensé ou dont le sens est diamétralement opposé à celui de la référence peut très bien avoir un score ROUGE très élevé.
Elle est très sensible aux changements de vocabulaire et à l'utilisation de synonymes.
Il est donc nécessaire d'utiliser le même vocabulaire dans la référence et les résumés.
Dans le cadre de l'extracting summarization, puisque les phrases sont tirées directement du texte, la syntaxe, le sens et le vocabulaire sont nécessairement les mêmes dans la référence et le résumé.
C'est pourquoi la métrique ROUGE se marie très bien avec cette méthode de summarization.